Primeros pasos con yfinance

yfinance es una popular biblioteca de código abierto desarrollada por Ran Aroussi como un medio para acceder a los datos financieros disponibles en Yahoo Finance.
Yahoo Finance ofrece una excelente variedad de datos de mercado sobre acciones, bonos, divisas y criptomonedas. También ofrece noticias, informes y análisis del mercado y, además, opciones y datos fundamentales, que lo distinguen de algunos de sus competidores.
Yahoo Finance solía tener su propia API oficial, pero esta fue desmantelada el 15 de mayo de 2017, luego de un uso indebido generalizado de los datos. En la actualidad, existe una variedad de API y bibliotecas no oficiales para acceder a los mismos datos, incluido, por supuesto, yfinance.
El principal inconveniente resultaría en la calidad de los datos, pues no se garantiza que estén bien. No deja de ser una API gratuita.
A continuación vamos a mostrar algunas de las funcionalidades de yfinance:
Realizamos un pequeño scrapping de tickers para tener algo con lo que trabajar para el ejemplo, en este caso los índices mundiales.
import yfinance as yf
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
import requests
url = 'https://finance.yahoo.com/world-indices'
ua = "Gozilla/5.0" # Mozilla
r = requests.get(url, headers={'User-Agent': ua})
indices = pd.read_html(r.text)[0]
indices_symbol = indices['Symbol'].tolist()
Con un bucle vamos a recorrer toda la lista de activos aplicando la función .info(). Nos mostrará información fundamental acerca del activo en cuestión en forma de diccionario {key:value}.
for t in indices_symbol:
stocks = yf.Ticker(t)
stocksinfo = stocks.info
print(stocksinfo)

La información se nos muestra compactada de tal forma que resulta visualmente desagradable de leer. Podemos tratar de separar los elementos.
for t in indices_symbol:
stocks = yf.Ticker(t)
stocksinfo = stocks.info
for key,value in stocksinfo.items():
print(key, ":",value)
Podemos utilizar también las funciones predefinidas para analizar información concreta. Os recomiendo que os leáis la documentación para conocer todo lo que ofrece esta API. La clase Ticker permite acceder a información de balances, cashflows, dividendos, accionistas...
ibm = yf.Ticker(ibm)
print(ibm.recommendations,ibm.dividends,ibm.major_holders) #Existen muchas más
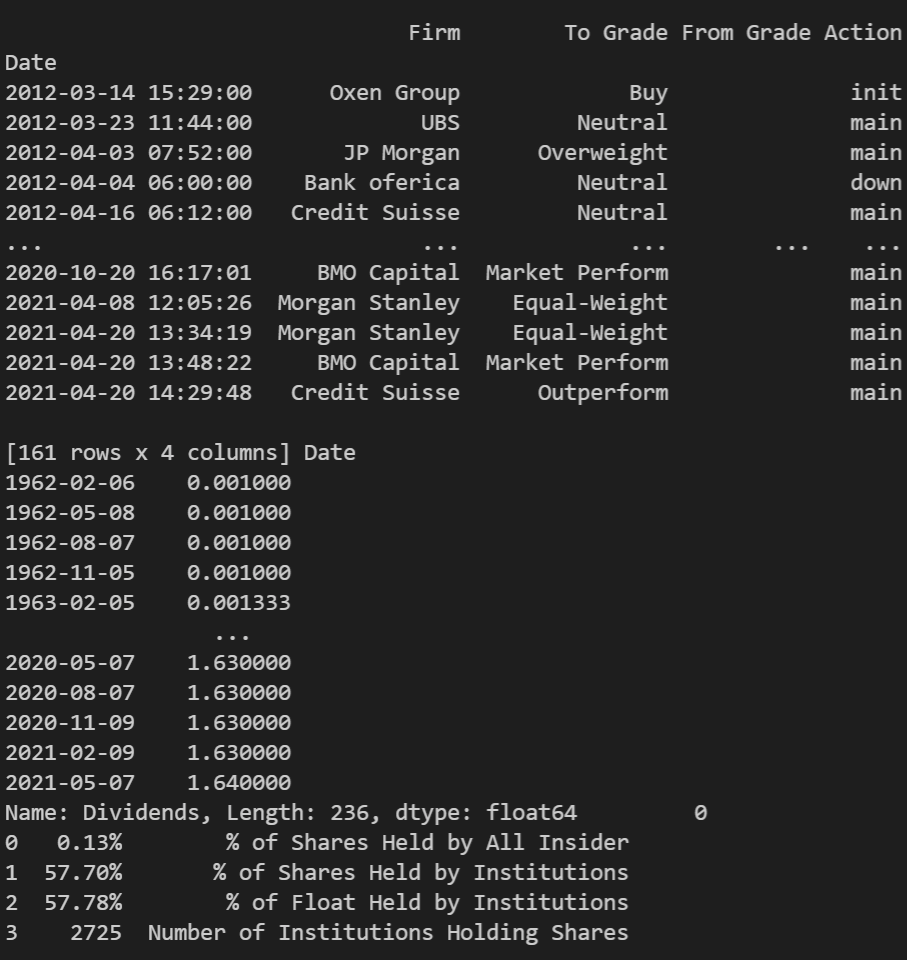
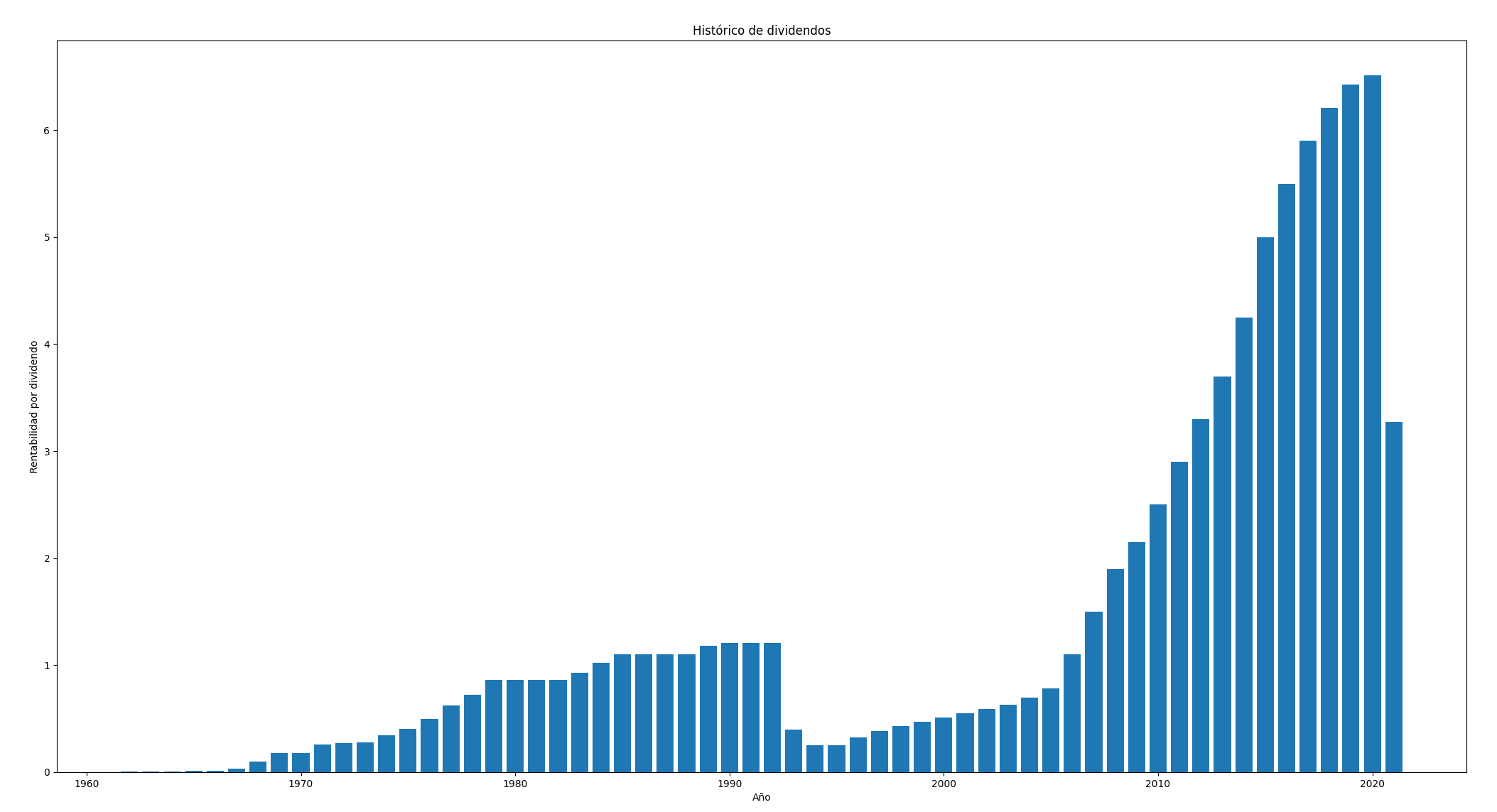
Vamos a realizar un ejemplo en el que a partir de la función dividendos, creamos un DataFrame calculando el acumulado anual:
df = ibm.dividends
data = df.resample('Y').sum()
data = data.reset_index()
data['Date'] = data['Date'].dt.year
Luego graficamos, poniendo las fechas en el eje de las abscisas:
plt.figure()
plt.bar(data['Date'], data['Dividends'])
plt.ylabel('Rentabilidad por dividendo')
plt.xlabel('Año')
plt.title('Histórico de dividendos')
plt.show()
Vamos a realizar algunos ejemplos más.
Haremos un bucle con el que pasarle la función .info() con .append() a una variable tipo lista de nuestra elección, con tickers que deseemos, en este caso un pequeño scrapping del Dow Jones.
Luego crearemos un DataFrame y le pasaremos los tickers al índice:
DJW = pd.read_html('https://en.wikipedia.org/wiki/Dow_Jones_Industrial_Average')[1]
DJW = list(DJW['Symbol'])
info = []
for i in DJW:
info.append(yf.Ticker(i).info)
df = pd.DataFrame(info)
df = df.set_index('symbol')

Crearemos una variable con el nombre de las columnas que nos interese mantener para crear nuestra tabla de entre todas las disponibles en la función:
symbol
zip
sector
fullTimeEmployees
longBusinessSummary
city
phone
state
country
companyOfficers
website
maxAge
address1
industry
ebitdaMargins
profitMargins
grossMargins
operatingCashflow
revenueGrowth
operatingMargins
ebitda
targetLowPrice
recommendationKey
grossProfits
freeCashflow
targetMedianPrice
currentPrice
earningsGrowth
currentRatio
returnOnAssets
numberOfAnalystOpinions
targetMeanPrice
debtToEquity
returnOnEquity
targetHighPrice
totalCash
totalDebt
totalRevenue
totalCashPerShare
financialCurrency
revenuePerShare
quickRatio
recommendationMean
exchange
shortName
longName
exchangeTimezoneName
exchangeTimezoneShortName
isEsgPopulated
gmtOffSetMilliseconds
quoteType
messageBoardId
market
annualHoldingsTurnover
enterpriseToRevenue
beta3Year
enterpriseToEbitda
52WeekChange
morningStarRiskRating
forwardEps
revenueQuarterlyGrowth
sharesOutstanding
fundInceptionDate
annualReportExpenseRatio
totalAssets
bookValue
sharesShort
sharesPercentSharesOut
fundFamily
lastFiscalYearEnd
heldPercentInstitutions
netIncomeToCommon
trailingEps
lastDividendValue
SandP52WeekChange
priceToBook
heldPercentInsiders
nextFiscalYearEnd
yield
mostRecentQuarter
shortRatio
sharesShortPreviousMonthDate
floatShares
beta
enterpriseValue
priceHint
threeYearAverageReturn
lastSplitDate
lastSplitFactor
legalType
lastDividendDate
morningStarOverallRating
earningsQuarterlyGrowth
priceToSalesTrailing12Months
dateShortInterest
pegRatio
ytdReturn
forwardPE
lastCapGain
shortPercentOfFloat
sharesShortPriorMonth
impliedSharesOutstanding
category
fiveYearAverageReturn
previousClose
regularMarketOpen
twoHundredDayAverage
trailingAnnualDividendYield
payoutRatio
volume24Hr
regularMarketDayHigh
navPrice
averageDailyVolume10Day
regularMarketPreviousClose
fiftyDayAverage
trailingAnnualDividendRate
open
toCurrency
averageVolume10days
expireDate
algorithm
dividendRate
exDividendDate
circulatingSupply
startDate
regularMarketDayLow
currency
trailingPE
regularMarketVolume
lastMarket
maxSupply
openInterest
marketCap
volumeAllCurrencies
strikePrice
averageVolume
dayLow
ask
askSize
volume
fiftyTwoWeekHigh
fromCurrency
fiveYearAvgDividendYield
fiftyTwoWeekLow
bid
tradeable
dividendYield
bidSize
dayHigh
regularMarketPrice
preMarketPrice
logo_url
columnsfundamentals = ['beta', 'marketCap', 'dividendYield', 'forwardPE',
'priceToBook','pegRatio','netIncomeToCommon','forwardEps','shortRatio', 'shortName' ]
Con el método .isin() comprobamos si existen los nombres de las columnas escogidas y se las pasamos a nuestro DataFrame (df), luego cambiamos los NaN por 0's:
df = df[df.columns[df.columns.isin(columnsfundamentals)]]
df = df.fillna(0)
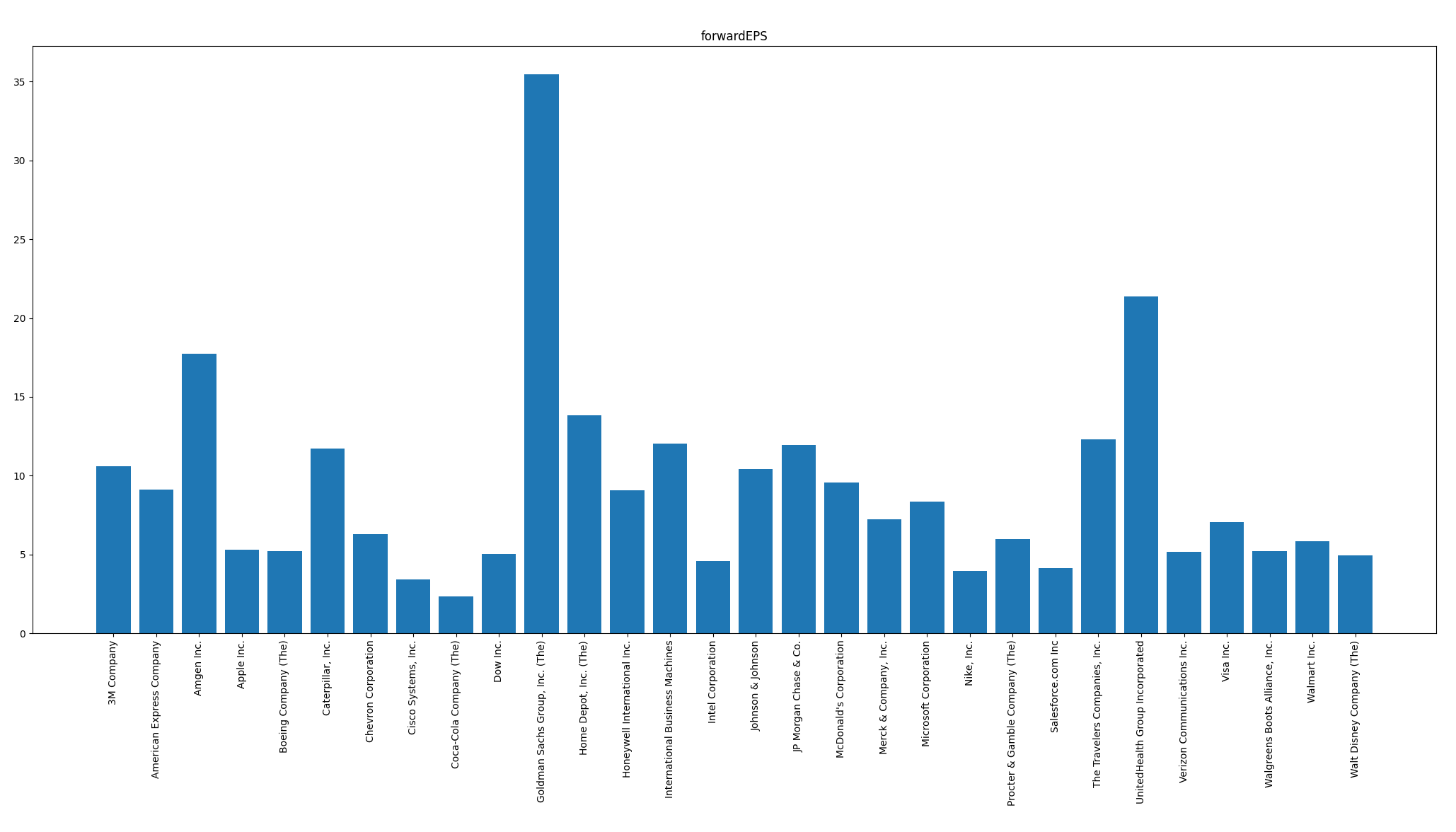
A continuación mostramos un gráfico de ejemplo, poniendo los nombres en el eje de las abscisas de forma invertida verticalmente y mostrando el forwardEPS:
plt.bar(df.shortName,df.forwardEps)
plt.title("forwardEPS")
plt.xticks(rotation=90)
plt.show()
4337 visitas
Categorías:
Estrategias Estadísticas Random Gestión pasiva Análisis técnico Modelos CEO Mapas mentales Liberalismo Python Growth Niusleta Ahorro Recursos humanos Inmobiliario Fiscalidad Value investing Dividendos Contabilidad Marketing Riesgo IF Cursos Opciones Bolsa