Random Forest Classifier (SP500)

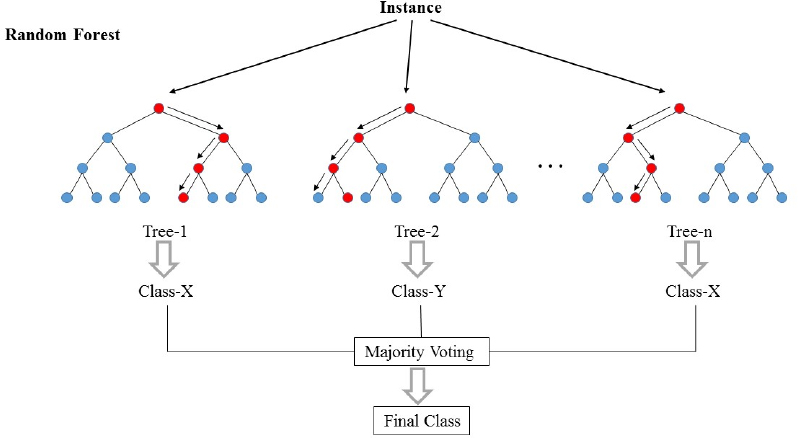
Antes de hablar del algoritmo Random Forest, debemos saber que éste está compuesto de múltiples árboles de decisión.
Los árboles de decisión (clasificación) son modelos predictivos formados por reglas binarias (si/no) con las que se consigue repartir las observaciones en función de sus atributos y predecir así el valor de una variable.

Un modelo Random Forest está formado por un conjunto (ensemble) de árboles de decisión individuales, cada uno entrenado con una muestra aleatoria extraída de los datos de entrenamiento originales mediante bootstrapping. A partir del conjunto de entrenamiento, el algoritmo genera un cierto número de árboles de decisión siendo entrenado cada uno de ellos con un conjunto aleatorio de muestras. Además, durante la división de cada nodo, en lugar de considerar todas las características para encontrar el mejor criterio de división, solo considera un subconjunto de ellas. Gracias a la librería Scikit-Learn se calcula el valor medio de las predicciones probabilísticas.
Muchos métodos predictivos generan modelos globales en los que una única ecuación se aplica a todo el espacio muestral. Cuando el caso de uso implica múltiples predictores, que interaccionan entre ellos de forma compleja y no lineal, es muy difícil encontrar un único modelo global que sea capaz de reflejar la relación entre las variables.
En general, el aprendizaje automático es increíblemente útil para tareas difíciles cuando tenemos información incompleta o información que es demasiado compleja para programarla a mano. En estos casos, podemos proporcionar la información que tenemos disponible para nuestro modelo y dejar que este "aprenda" la información que falta por sí misma. El algoritmo luego utilizará técnicas estadísticas para extraer el conocimiento faltante directamente de los datos.
Los métodos estadísticos y de machine learning basados en árboles engloban a un conjunto de técnicas supervisadas que consiguen segmentar el espacio de los predictores en regiones simples, dentro de las cuales es más sencillo manejar las interacciones. Es esta característica la que les proporciona gran parte de su potencial.
A continuación os muestro un ejemplo del algoritmo:
RFC aplicado al SP500 (Proof of concept)
Los retornos de mañana serán mayores que 0?
Primero importamos las librerías que necesitaremos, especialmente los módulos para el algoritmo, de la biblioteca sklearn.
import pandas_datareader.data as wb
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
from sklearn.ensemble import RandomForestClassifier
Dejamos preparada nuestra descarga de datos del SP500 y en una variable llamada returns le calculamos los retornos diarios simples hasta la fecha:
ticker = "^GSPC"
data = wb.DataReader(ticker, 'yahoo', '2010-1-1')
returns = data['Close'].pct_change()
Calculamos una serie de indicadores técnicos que usaremos como variables predictivas del modelo.
Escoger el número y el tipo de variables del modelo es una parte crucial, si buscáramos realismo no deberíamos centrarnos únicamente en indicadores técnicos. Resultados empresariales, macro, mmpp, insiders... son muchas opciones las que tenemos a la hora de decidir cómo enriquecer el modelo, para esta prueba de concepto utilizaremos las siguientes:
%Var. Apertura-Cierre, %Var Máx-Mín diario, desviación estándar, media, medias móviles (aceleraciones), MACD, RSI, %K, Volumen...
data['Open-Close'] = (data.Open - data.Close)/data.Open
data['High-Low'] = (data.High - data.Low)/data.Low
data['std'] = returns.rolling(30).std()
data['mean'] = returns.rolling(30).mean()
ema5 = data['Close'].ewm(span=5, min_periods=5).mean()
ema10 = data['Close'].ewm(span=10, min_periods=10).mean()
ema30 = data['Close'].ewm(span=30, min_periods=30).mean()
data['EMA5>EMA10']= np.where(ema5 > ema10, 1, -1)
data['EMA10>EMA30']= np.where(ema10 > ema30, 1, -1)
data['Cl>EMA5']= np.where(data['Close'] > ema5, 1, -1)
data['Cl>EMA10']= np.where(data['Close'] > ema10, 1, -1)
exp1 = data['Close'].ewm(span=12, min_periods=12).mean()
exp2 = data['Close'].ewm(span=26, min_periods=26).mean()
macd = exp1 - exp2
macd_signal = macd.ewm(span=9).mean()
data['MACD'] = macd_signal - macd
up = returns.clip(lower=0)
down = -1*returns.clip(upper=0)
ema_up = up.ewm(com=14, adjust=False).mean()
ema_down = down.ewm(com=14, adjust=False).mean()
rs = ema_up/ema_down
data['RSI'] = 100-(100/(1+rs))
high14= data['High'].rolling(14).max()
low14 = data['Low'].rolling(14).min()
data['%K'] = (data['Close'] - low14)*100/(high14 - low14)
La variable a predecir: El retorno del SP500 de mañana será mayor que 0?
data['Return'] = returns.shift(-1)
data['Class'] = np.where(data['Return'] > 0, 1, 0)
Limpiamos posibles filas erróneas:
data = data.dropna()
Creamos la variable con los predictores y organizamos en X e y nuestras variables dependientes e independientes para pasárselas al modelo
predictors = ['High-Low', 'Open-Close', 'EMA5>EMA10', 'EMA10>EMA30', 'Cl>EMA10', 'Cl>EMA5', 'mean', 'std', 'MACD', 'RSI', '%K' ,'Volume']
X = data[predictors]
y= data['Class']
Utilizamos el módulo train_test_split para dividir nuestra data entre entrenamiento y testeo, 70/30 para el ejemplo.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Le pasamos .fit() al modelo RandomForestClassifier y le pasamos .()predict a X_test
rfc = RandomForestClassifier(random_state=0)
rfc = rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
Mostramos resultados por pantalla: classification_report y accuracy_score
report = classification_report(y_test, y_pred)
print("\nModel Accuracy: ", accuracy_score(y_test, y_pred, normalize=True))
print("\n", report)
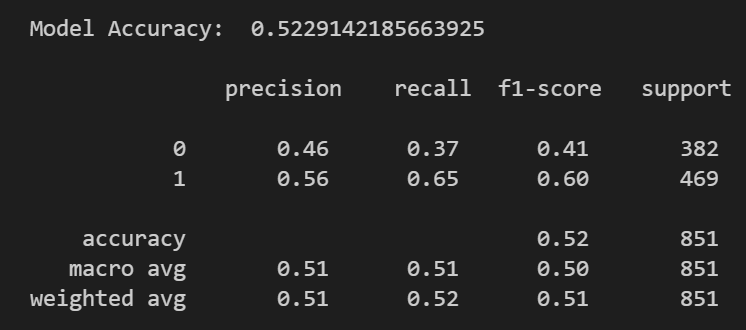
En esta prueba de concepto, la precisión es del 52%, y hay un 56% de que los retornos sean mayor que 0 (1).
Existe mucho margen de mejora, escogiendo bien el periodo y el número de datos, trabajando bien la muestra tanto de entrenamiento como de testeo y escogiendo otro tipo de predictores.
Aquí tenéis el código completo:
import pandas_datareader.data as wb
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
from sklearn.ensemble import RandomForestClassifier
ticker = "^GSPC"
data = wb.DataReader(ticker, 'yahoo', '2010-1-1')
returns = data['Close'].pct_change()
data['Open-Close'] = (data.Open - data.Close)/data.Open
data['High-Low'] = (data.High - data.Low)/data.Low
data['std'] = returns.rolling(30).std()
data['mean'] = returns.rolling(30).mean()
ema5 = data['Close'].ewm(span=5, min_periods=5).mean()
ema10 = data['Close'].ewm(span=10, min_periods=10).mean()
ema30 = data['Close'].ewm(span=30, min_periods=30).mean()
data['EMA5>EMA10']= np.where(ema5 > ema10, 1, -1)
data['EMA10>EMA30']= np.where(ema10 > ema30, 1, -1)
data['Cl>EMA5']= np.where(data['Close'] > ema5, 1, -1)
data['Cl>EMA10']= np.where(data['Close'] > ema10, 1, -1)
exp1 = data['Close'].ewm(span=12, min_periods=12).mean()
exp2 = data['Close'].ewm(span=26, min_periods=26).mean()
macd = exp1 - exp2
macd_signal = macd.ewm(span=9).mean()
data['MACD'] = macd_signal - macd
up = returns.clip(lower=0)
down = -1*returns.clip(upper=0)
ema_up = up.ewm(com=14, adjust=False).mean()
ema_down = down.ewm(com=14, adjust=False).mean()
rs = ema_up/ema_down
data['RSI'] = 100-(100/(1+rs))
high14= data['High'].rolling(14).max()
low14 = data['Low'].rolling(14).min()
data['%K'] = (data['Close'] - low14)*100/(high14 - low14)
data['Return'] = returns.shift(-1)
data['Class'] = np.where(data['Return'] > 0, 1, 0)
data = data.dropna()
predictors = ['High-Low', 'Open-Close', 'mean', 'std', 'EMA5>EMA10','EMA10>EMA30','Cl>EMA5','Cl>EMA10','MACD', 'RSI', '%K' ,'Volume']
X = data[predictors]
y= data['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
rfc = RandomForestClassifier(random_state=0)
rfc = rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
report = classification_report(y_test, y_pred)
print("\nModel Accuracy: ", accuracy_score(y_test, y_pred, normalize=True))
print("\n", report)
823 visitas
Categorías:
Estrategias Estadísticas Random Gestión pasiva Análisis técnico Modelos CEO Mapas mentales Liberalismo Python Growth Niusleta Ahorro Recursos humanos Inmobiliario Fiscalidad Value investing Dividendos Contabilidad Marketing Riesgo IF Cursos Opciones Bolsa