Scrapping de datos de Yahoo Finance

Existen múltiples librerías en Python para realizar "Web Scrapping" (BeautifulSoup, requests...), una técnica no muy friendly para las empresas, en las que un usuario puede consultar y descargar datos de forma no concebida inicialmente por el creador de la web. Dependiendo del "bandwith" o ancho de banda contratado, podríamos ocasionar un ataque DoS sin pretenderlo y que nos consideren como malicioso, bloqueándonos la IP o a través de una denúncia en los casos más extremos.
Para el siguiente ejemplo necesitaremos el intérprete Python junto con la librería LXML y Pandas, que ya conocemos.
El objetivo de la práctica es poder descargar datos de forma rápida y automatizada los datos financieros de una empresa.
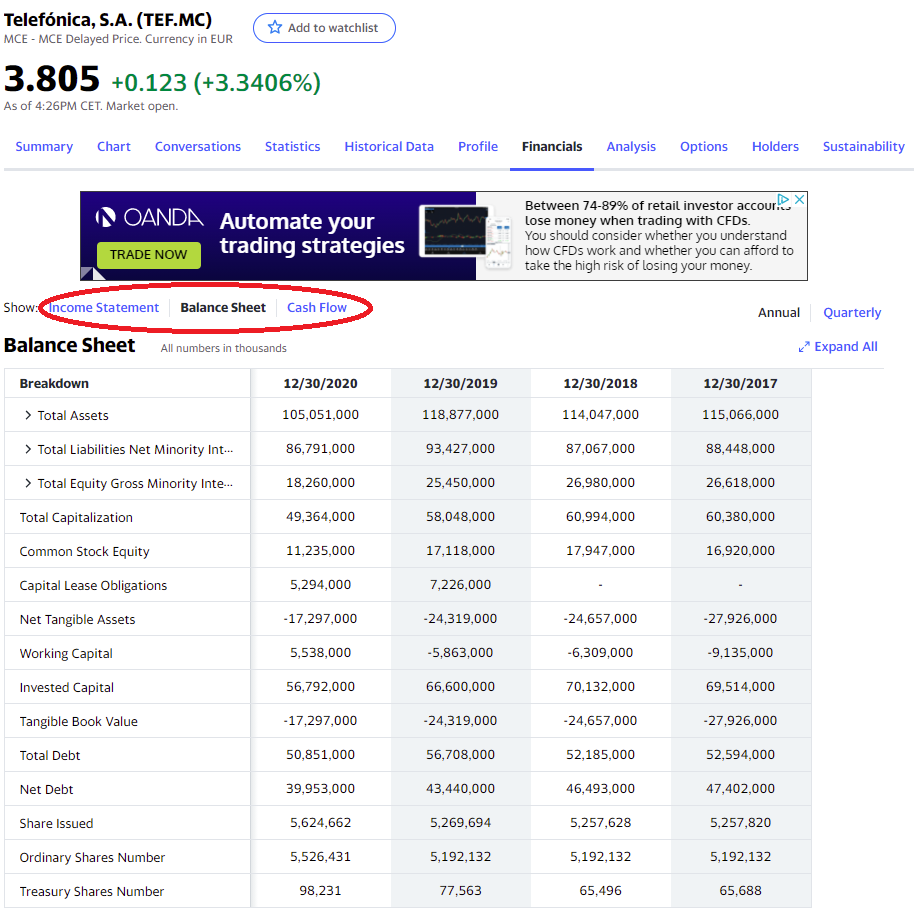
La calidad de los datos, como apuntaba Ramon Secora, deja mucho que desear, pero es la única página conocida de la que extraer datos financieros sin limitación de requests (velocidad) y fácilmente automatizable, a la vez que perdurable, ya que no suele ofrecer barreras de entrada considerables a la extracción de sus datos.
Primero empezamos importando las librerías:
from datetime import datetime
from lxml import html
import requests
import numpy as np
import pandas as pd
Acto seguido definimos una variable que actuará de ticker, configurable por el usuario, y declaramos la/s url. En el siguiente ejemplo se descarga por defecto la hoja de Balance, pero podemos cambiar la url para descargar los ratios financieros o la hoja de los flujos de caja.
En caso de querer las 3, una forma fácil de hacerlo es triplicando el código, declarando las variables para cada url.
symbol = 'TEF.MC'
url = 'https://finance.yahoo.com/quote/' + symbol + '/balance-sheet?p=' + symbol
# 'https://finance.yahoo.com/quote/' + symbol + '/financials?p=' + symbol FINANCIALS
# 'https://finance.yahoo.com/quote/' + symbol + '/cash-flow?p=' + symbol CASH-FLOWS
Definimos unos headers a través de los que se realizarán las consultas.
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9',
'Cache-Control': 'max-age=0',
'Pragma': 'no-cache',
'Referrer': 'https://google.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
Con page cogemos la página con los headers, con tree "parseamos" la página con LXML para hacer nuestras consutlas XPATH.
page = requests.get(url, headers)
tree = html.fromstring(page.content)
tree.xpath("//h1/text()")
A continuación detectamos si existen table_rows y en caso afirmativo procedemos a descargarlos en parsed_rows con un bucle y lo mostramos por pantalla.
Añadimos también la funcionalidad de generar un archivo *.xlsx con la librería Openpyxl y pandas con ExcelWriter indicándole un datetime, para posteriormente pasarle el dataframe.
table_rows = tree.xpath("//div[contains(@class, 'D(tbr)')]")
assert len(table_rows) > 0
parsed_rows = []
for table_row in table_rows:
parsed_row = []
el = table_row.xpath("./div")
none_count = 0
for rs in el:
try:
(text,) = rs.xpath('.//span/text()[1]')
parsed_row.append(text)
except ValueError:
parsed_row.append(np.NaN)
none_count += 1
if (none_count < 4):
parsed_rows.append(parsed_row)
df = pd.DataFrame(parsed_rows)
date = datetime.today().strftime('%Y-%m-%d')
writer = pd.ExcelWriter('Datos-de '+ symbol +" "+ date + ' .xlsx')
df.to_excel(writer)
writer.save()
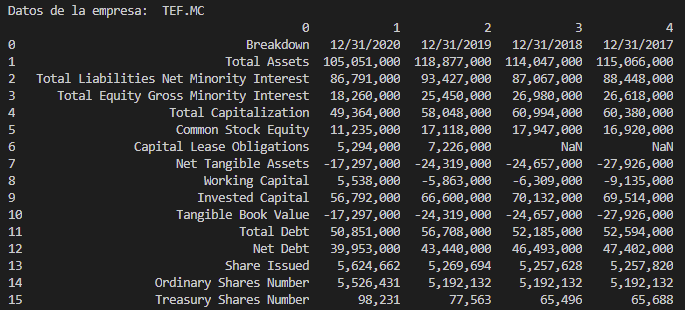
print("\n"+"Datos de la empresa: ", symbol)
print(df)
Aquí tenéis el script entero:
from datetime import datetime
from lxml import html
import requests
import numpy as np
import pandas as pd
symbol = 'TEF.MC'
url = 'https://finance.yahoo.com/quote/' + symbol + '/balance-sheet?p=' + symbol
# 'https://finance.yahoo.com/quote/' + symbol + '/financials?p=' + symbol FINANCIALS
# 'https://finance.yahoo.com/quote/' + symbol + '/cash-flow?p=' + symbol CASH-FLOWS
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9',
'Cache-Control': 'max-age=0',
'Pragma': 'no-cache',
'Referrer': 'https://google.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
page = requests.get(url, headers)
tree = html.fromstring(page.content)
tree.xpath("//h1/text()")
table_rows = tree.xpath("//div[contains(@class, 'D(tbr)')]")
assert len(table_rows) > 0
parsed_rows = []
for table_row in table_rows:
parsed_row = []
el = table_row.xpath("./div")
none_count = 0
for rs in el:
try:
(text,) = rs.xpath('.//span/text()[1]')
parsed_row.append(text)
except ValueError:
parsed_row.append(np.NaN)
none_count += 1
if (none_count < 4):
parsed_rows.append(parsed_row)
df = pd.DataFrame(parsed_rows)
date = datetime.today().strftime('%Y-%m-%d')
writer = pd.ExcelWriter('Datos-de '+ symbol +" "+ date + ' .xlsx')
df.to_excel(writer)
writer.save()
print("\n"+"Datos de la empresa: ", symbol)
print(df)
1672 visitas
Categorías:
Estrategias Estadísticas Random Gestión pasiva Análisis técnico Modelos CEO Mapas mentales Liberalismo Python Growth Niusleta Ahorro Recursos humanos Inmobiliario Fiscalidad Value investing Dividendos Contabilidad Marketing Riesgo IF Cursos Opciones Bolsa