Tactical Asset Allocation: CAGR de carteras equiponderadas al azar por correlación

Entendemos por asset allocation la estrategia por la que un inversor decide cómo distribuir sus inversiones entre las diferentes clases de activos que existen. En otras palabras, es la manera de dividir tu cartera entre acciones, bonos, efectivo, inversiones inmobiliarias, alternativas...
Es un factor determinante de la rentabilidad de una cartera.
En este artículo vamos a hablar sobre cómo generar carteras al azar, para un número de activos con unos pesos determinados, de entre una muestra de ETF's de todo tipo.
Vamos a trabajar con una muestra disponible de 1000 ETF's distintos, lo cual nos va a permitir, partiendo de un filtro por correlación, ser capaz de generar carteras estratégicas y comprobar su rentabilidad o CAGR para un periodo.
import random
import pandas as pd
import investpy
import yfinance as yf
import matplotlib.pyplot as plt
import numpy as np
tickers = investpy.get_etfs_overview(country="United States", n_results=1000)
tickers = list(tickers['symbol'])
df = yf.download(tickers,start='2018-01-01', progress=False)['Close']
returns = df.pct_change()[1:]
Descargamos la muestra total disponible de la función get_etfs_overview() de investpy para Estados Unidos.
Descargamos también los precios de cierre partiendo de 2018 (por ejemplo) y calculamos los retornos con pct_change().
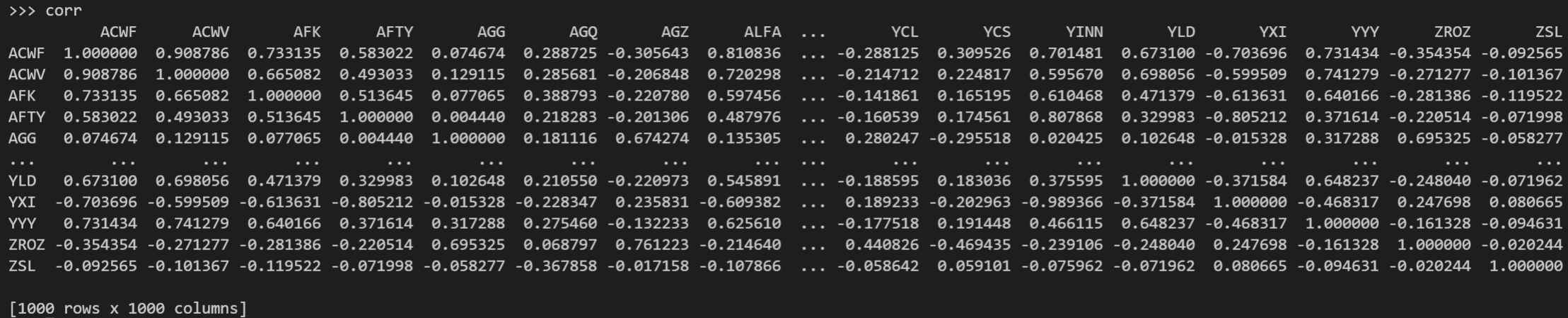
corr = returns.corr(method='pearson')
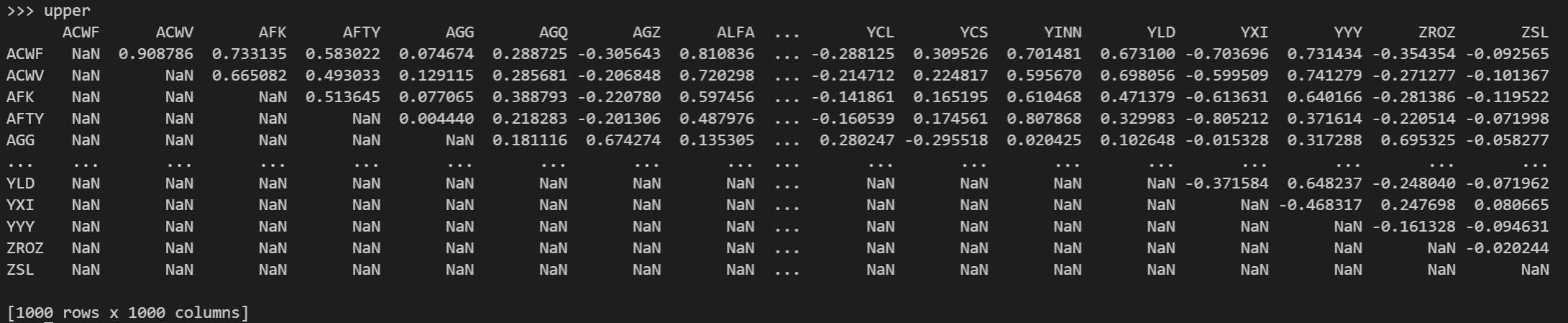
upper = corr.where(np.triu(np.ones(corr.shape), k=1).astype(np.bool8))
upper = upper.unstack().dropna()
upper = upper.sort_values(ascending=False)
Calculamos la correlación de Pearson y se nos genera una matriz 1000x1000 (se compara cada activo entre todos ellos), nos quedamos con la matriz triangular superior excluyendo cada valor comparado con sí mismo, desempaquetamos la matriz en series, eliminamos los 'NaN' de la matriz triangular inferior y ordenamos nuestra muestra de mayor a menor correlación.

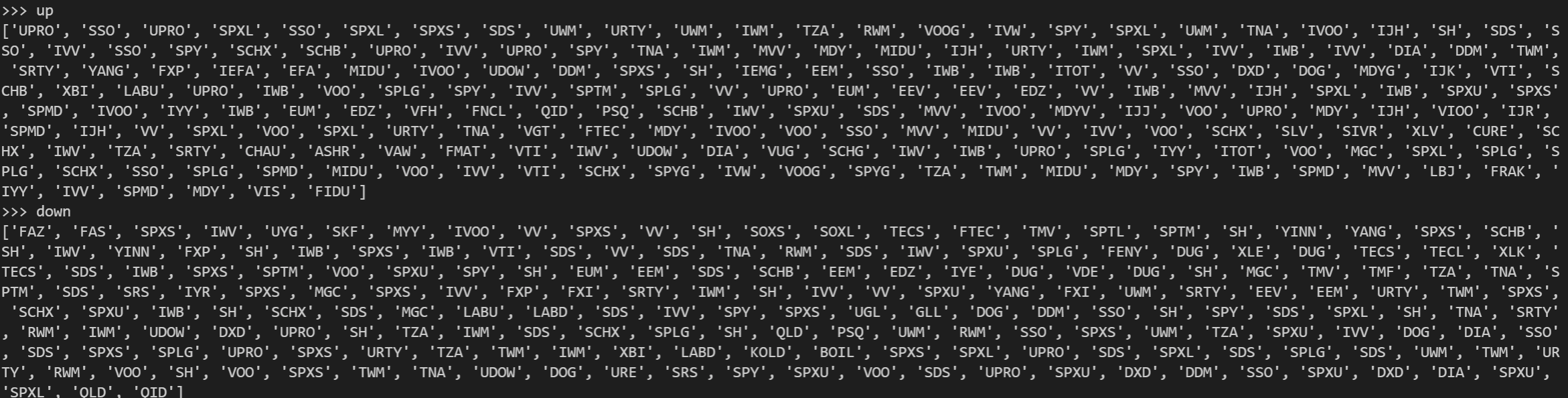
up = upper[:200]
up = [item for t in up.index for item in t]
down = upper[-200:]
down = [item for t in down.index for item in t]
Vamos a seleccionar, por ejemplo, 2 muestras, una con los 200 primeros ETF más correlacionados, y otra con los 200 que lo están menos. Uno de los problemas con el que nos encontramos, es que algunos ETF pueden estar entre los más y menos correlacionados a la vez, con lo que en algún momento habrá que eliminar los duplicados para curar la muestra.
cagr= pd.DataFrame(index=df.index)
Rdom= []
Creamos un dataframe con el índice de la serie temporal de los precios, y una lista que va a contener, de forma iterativa, los tickers de cada cartera generada al azar.
for i in range(12):
randometf = list(set(random.sample(up,k=5) + random.sample(down,k=5)))
while len(randometf)<10:
randometf = list(set(random.sample(up,k=5) + random.sample(down,k=5)))
Rdom.append(randometf)
data = yf.download(randometf,'2020-01-01', progress=False)['Close']
weights = [1/len(randometf)]*len(randometf)
#weights = np.random.random(len(randometf))
#weights /= np.sum(weights)
returns = data.pct_change()
returns = returns.dot(weights)
cagr[i] = (1 + returns).cumprod().fillna(1)
print('Random',i,Rdom[i])
plt.style.use('seaborn')
cagr.plot(figsize=(22,12), title="Carteras equiponderadas con ETF al azar de entre una muestra con los" + str(len(up)) + " más correlacionados y los" + str(len(down)) +" menos correlacionados.", ylabel="CAGR", xlabel="Fechas")
plt.legend(Rdom)
plt.show()
Creamos un bucle for con un número de iteraciones determinado (cada iteración será una cartera), generamos una muestra aleatoria jugando con nuestras muestras de ETF ordenados, en este caso selecciono 5 de entre los más correlacionados y 5 de entre los que lo están menos.
El bucle while lo utilizo para curar la data y eliminar duplicados con la clase set(), si no podría tener listas con activos repetidos.
Con este script somos capaces de generar el número de carteras y activos que vosotros queráis, sin limitación, y los podéis escoger de cualquier tipo de segmentación de la correlación que hayáis hecho.
La matriz de los pesos "weights", en este caso, es una lista con pesos en tanto por uno (tiene que ser homogéneo con los retornos) para el número exacto de activos seleccionados en randometf. Podéis hacer los pesos aleatorios siempre y cuando el total de la matriz sea el 100% (sume 1 o 100 en %).
A continuación calculamos el CAGR para cada cartera ponderada que nos haya tocado, 12 carteras de 10 activos equiponderados en este ejemplo en concreto, y graficamos.

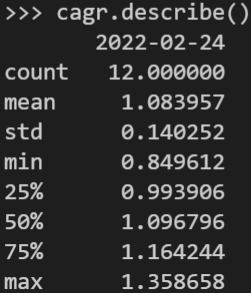
Este sería el resultado de nuestras 12 carteras. Lo ideal sería hacer un muestreo amplio y analizar los resultados de la última fecha.
Un pequeño ejemplo:
cagr = cagr.iloc[-1]
cagr.describe()
Os dejo el código entero:
import random
import pandas as pd
import investpy
import yfinance as yf
import matplotlib.pyplot as plt
import numpy as np
tickers = investpy.get_etfs_overview(country="United States", n_results=1000)
tickers = list(tickers['symbol'])
df = yf.download(tickers,start='2018-01-01', progress=False)['Close']
returns = df.pct_change()[1:]
corr = returns.corr(method='pearson')
upper = corr.where(np.triu(np.ones(corr.shape), k=1).astype(np.bool8))
upper = upper.unstack().dropna()
upper = upper.sort_values(ascending=False)
upper
up = upper[:100]
up = [item for t in up.index for item in t]
down = upper[-100:]
down = [item for t in down.index for item in t]
cagr= pd.DataFrame(index=df.index)
Rdom= []
for i in range(12):
randometf = list(set(random.sample(up,k=5) + random.sample(down,k=5)))
while len(randometf)<10:
randometf = list(set(random.sample(up,k=5) + random.sample(down,k=5)))
Rdom.append(randometf)
data = yf.download(randometf,'2020-01-01', progress=False)['Close']
weights = [1/len(randometf)]*len(randometf)
#weights = np.random.random(len(randometf))
#weights /= np.sum(weights)
returns = data.pct_change()
returns = returns.dot(weights)
cagr[i] = (1 + returns).cumprod().fillna(1)
print('Random',i,Rdom[i])
plt.style.use('seaborn')
cagr.plot(figsize=(22,12), title="Carteras equiponderadas con ETF al azar de entre una muestra con los" + str(len(up)) + " más correlacionados y los" + str(len(down)) +" menos correlacionados.", ylabel="CAGR", xlabel="Fechas")
plt.legend(Rdom)
cagr = cagr.iloc[-1]
cagr.describe()
plt.show()
844 visitas
Categorías:
Estrategias Estadísticas Random Gestión pasiva Análisis técnico Modelos CEO Mapas mentales Liberalismo Python Growth Niusleta Ahorro Recursos humanos Inmobiliario Fiscalidad Value investing Dividendos Contabilidad Marketing Riesgo IF Cursos Opciones Bolsa