Introducción a Python para financieros

Aprender Python teniendo una base financiera es una magnífica forma de empezar en el mundo de la programación, si desgraciadamente somos foráneos en la materia.
Python es un lenguaje que consigue ser altamente escalable y hace uso de múltiples librerías “Open Source” que facilitan crear programas ya que importamos (import) código previamente escrito.
A diferencia de un lenguaje compilado clásico, Python es mayormente interpretado. Los lenguajes interpretados generalmente tienen un tiempo de desarrollo más reducido y se pueden detectar errores en el código mientras se desarrolla, lo cual es positivo, pero a la hora de ejecutarlo éste se procesa más lentamente.
Existe determinado consenso (PEP8) a la hora de utilizar Python. Consiste en una guía de estilo y estándares que, si bien no son obligatorios, son altamente recomendables y ayudan a la lectura y comprensión del programa a cualquier persona ajena, obviando la necesidad de comentar parcial o totalmente el código y así ahorrar tiempo. Se consideran buenas prácticas.
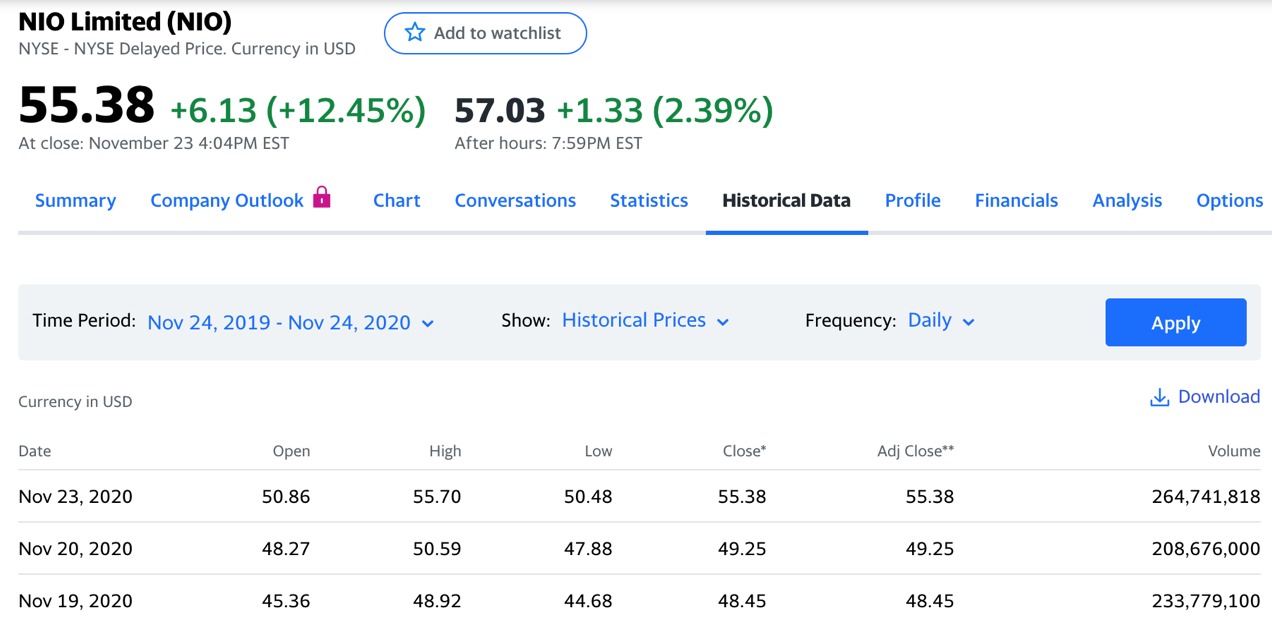
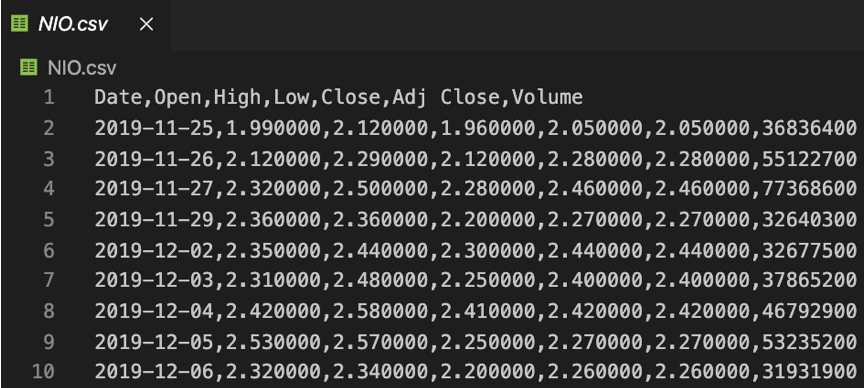
Para el ejemplo introductorio que tengo preparado, necesitaremos descargarnos un archivo *.csv con los parámetros de Fecha, Apertura, Máximo, Mínimo y Cierre de una acción. Para este ejemplo he descargado los datos de un año entero con fecha 24 de Noviembre en $NIO desde Yahoo Finance, siéntete libre de descargar el que te apetezca, siempre que contenga los parámetros previamente mencionados.
El entorno de desarrollo es algo personal de cada uno, en mi caso particular usaré Visual Studio code y trabajaré en entornos virtuales creados con pipenv, que nos permite concretar versiones y librerías para carpetas o entornos específicos.
Vamos a aprender a utilizar una serie de librerías Open Source que os deberíais instalar para continuar: pandas, plotly, matplotlib, seaborn, numpy.
cd /ruta/de/instalación
pipenv update
pipenv install pandas numpy plotly matplotlib seaborn
Esto debería generarnos el siguiente archivo Pipfile:
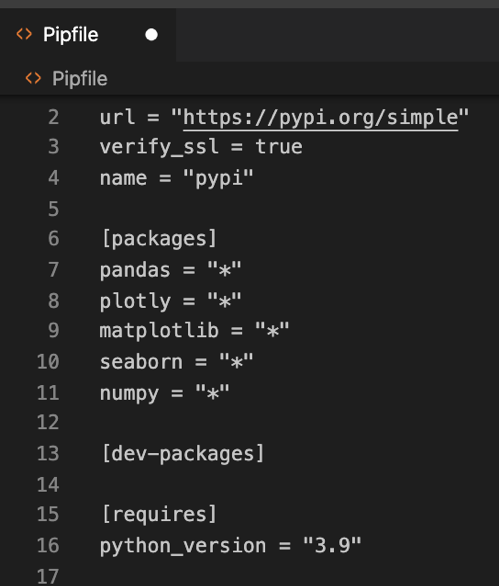
Nos servirá de indicador para saber si lo tenemos todo bien. A continuación analizamos el siguiente script:
import plotly.graph_objects as go
import pandas as pd
def create_chart(df):
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'])])
fig.show()
if __name__ == '__main__':
create_chart(pd.read_csv('NIO.csv'))
Este script tiene 3 partes definidas. La parte superior en la que el programa carga las librerías con el comando "import", ya sean 3rd parties o en el propio core del lenguaje, para luego llamarlas de forma acortada (go, pd) más adelante.
A continuación tenemos una función def llamada create_chart donde le pasamos el argumento df que utilizaremos para relacionar las columnas del *.csv: Open, High, Low y Close, y utilizamos Date para el eje de las "x".
En cuanto al if, es la forma de ejecutar un script en python directamente desde la terminal y lo que hace básicamente es diferenciar si el script es el principal o es un import. La variable __name__ la asigna el compilador con __main__ si es el archivo ejecutado o con el nombre del módulo o librería si es un archivo importado.
El resultado es el siguiente:
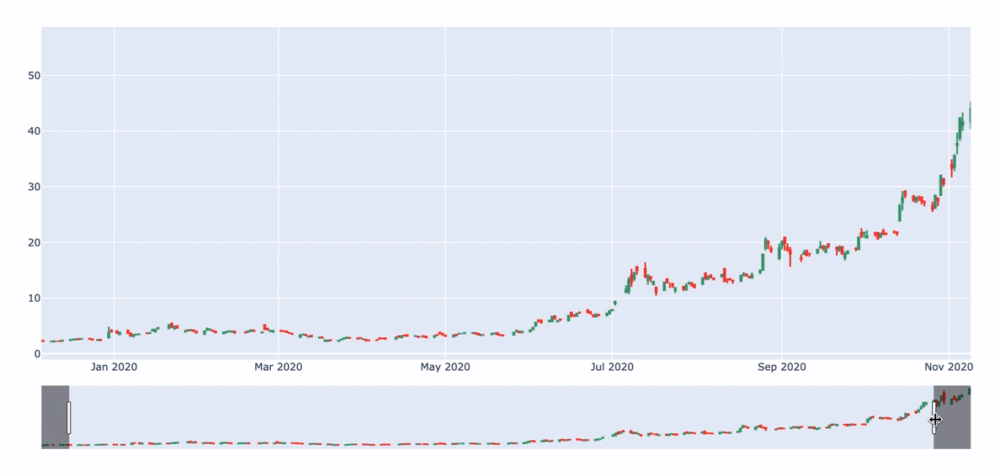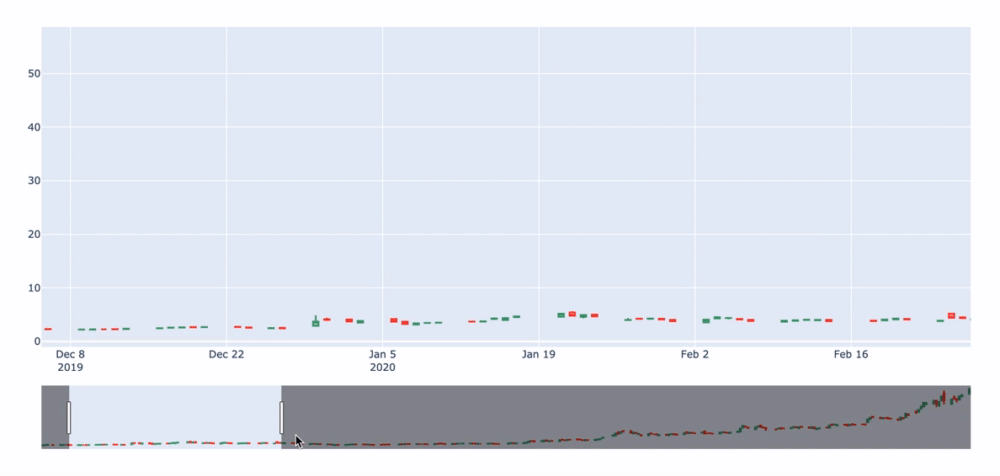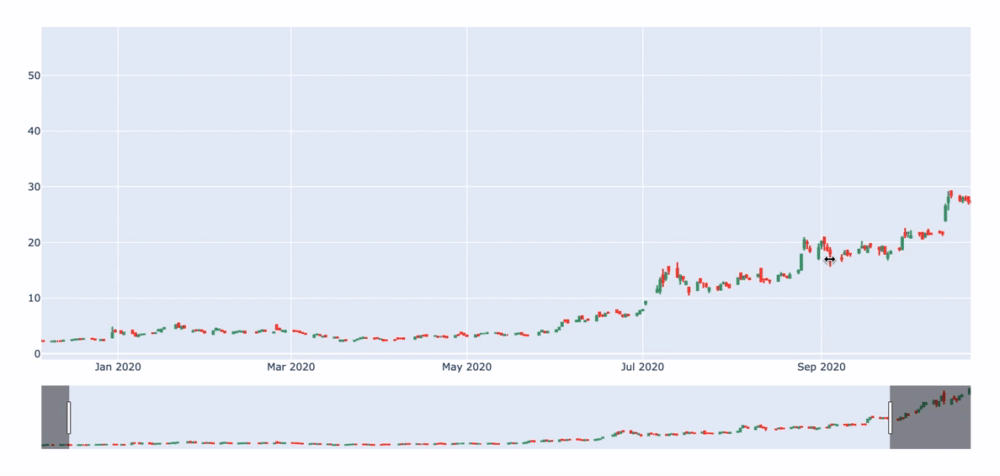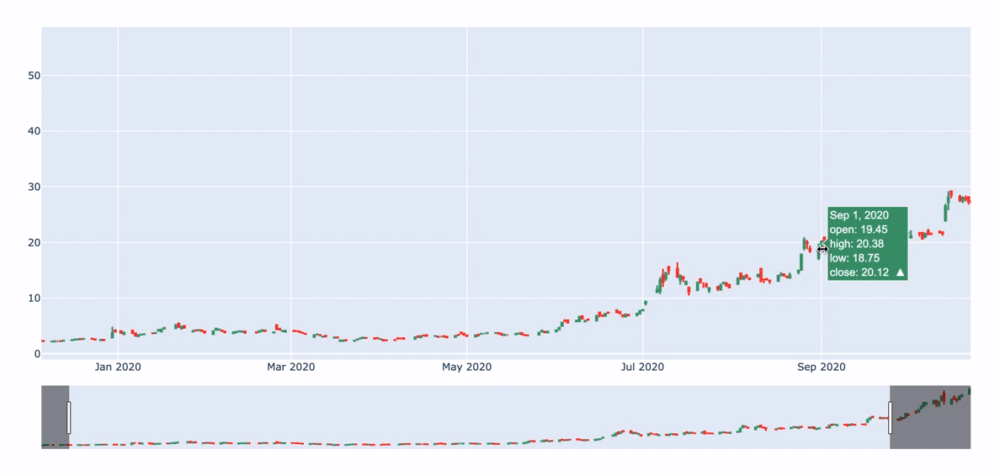
Espero que no te hubieras hecho demasiadas ilusiones...
Este ejemplo, sin embargo, nos introduce de forma amable a aprender a graficar un archivo *.csv. Visto así ya resulta más interesante.
Para el siguiente ejemplo, ahora que ya conocemos el csv, podemos aprender a generar datos de forma "aleatoria" con la librería random, que utilizaremos a continuación.
import csv
import random
with open('dist.csv', 'w', newline='') as f_output:
csv_output = csv.writer(f_output)
for _ in range(100):
numbers = random.randint(0, 10)
csv_output.writerow([numbers])
Este ejemplo nos permite, por una parte, la carga de las librerías random y csv para crear un archivo dist.csv.
Con el método random.randint(0,10) somos capaces de generar valores aleatorios enteros entre 0 y 10, para a continuación pasarlos a un archivo *.csv en la columna "numbers" (el número que determine el bucle for, que son 100 en este caso) de nombre dist.csv. Utilizamos el bucle for para iterar un bloque de instrucciones un número de veces.
No deja de ser un ejemplo sencillo.
Con la suficiente imaginación deberíamos ser capaces de jugar a nuestro antojo con los números para producir distribuciones con parámetros diferentes, así como estudiar la librería para tratar de mejorar o complementar el script.
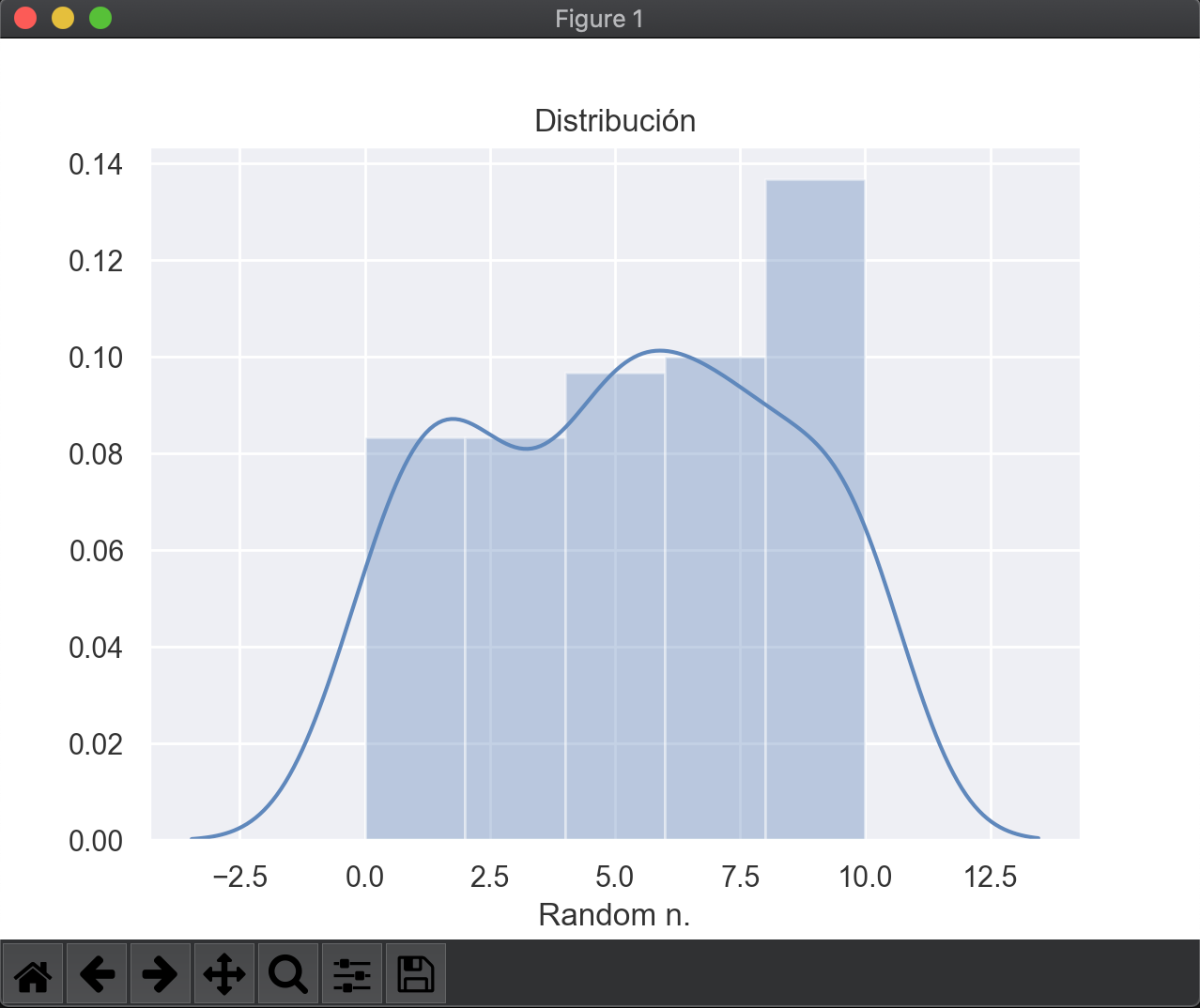
Gracias a disponer de esta distribución podemos trabajar con ella, y en este ejemplo os muestro cómo tratar de graficarla de la manera más sencilla con matplotlib:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
data = np.genfromtxt('dist.csv', delimiter=',')
sns.set(color_codes=True)
sns.distplot(data)
plt.title('Distribución normal?')
plt.xlabel('Random N.')
plt.ylabel('')
plt.show()
En mi caso particular he obtenido algo parecido a una distribución "normal", si es que se le puede llamar así  .
.
Espero que os pueda servir esta mini-introducción a diferentes librerías de estadística cuantitativa de Python. Tenéis enlaces a sus respectivas documentaciones por si queréis profundizar.

P.D.: El propio back-end de esta web está programado también en Python  .
.

1950 visitas
Categorías:
Estrategias Estadísticas Random Gestión pasiva Análisis técnico Modelos CEO Mapas mentales Liberalismo Python Growth Niusleta Ahorro Recursos humanos Inmobiliario Fiscalidad Value investing Dividendos Contabilidad Marketing Riesgo IF Cursos Opciones Bolsa