Introducción a Python para financieros (Parte II)

En esta segunda parte vamos a aprender a realizar cálculos con retornos, matrices, correlaciones, etc... para desenvolvernos mejor con el lenguaje y poder empezar a vislumbrar la construcción de algún modelo más complejo en futuras entregas.
En caso de necesidad, podemos volver a reactivar nuestro entorno virtual escribiendo en nuestra terminal o entorno de trabajo:
cd /ruta/de/instalación
pipenv shell
Tendremos nuestro entorno preparado con las librerías que instalamos ayer, que sólo afectan a esta ruta de trabajo en la que estamos.
Una de las necesidades más indispensables cuando trabajamos con acciones es el hecho de poder descargar información. En el artículo introductorio se comenta la posibilidad de descargar archivos a través de la web de Yahoo finance. La realidad es que esto se puede hacer de otra forma mucho más rápidamente.
Con este pequeño script descargaremos los precios de cierre ajustados de los tickers de las empresas que forman parte de la lista de la variable assets, empezando por el 1 de enero de 2020 y los grabaremos en un archivo llamado stocks_data.csv.
import pandas as pd
import numpy as np
import csv
from pandas_datareader import data as wb
assets = ['MSFT','UNP','GOOG','IBM']
data = pd.DataFrame()
data = wb.DataReader(assets,data_source='yahoo', start='2020-1-1')['Adj Close']
data.to_csv('stocks_data.csv')
Con pandas_datareader accedemos a la base de yahoo finance y le pasamos la variable assets que contiene una lista con los tickers que introduzcamos. Podemos cambiar a voluntad esa lista por otros tickers y descargar información sobre otros valores. Si eliminamos ['Adj Close'], por defecto se nos descargarán también los máximos, mínimos, apertura, cierre , volúmen y el cierre ajustado, que es el precio real en caso de que la empresa vaya a dar dividendo, realizar un split o contrasplit, etc...
La fecha es también modificable y podemos añadir el parámetro end para delimitar la finalización del bucle. En este caso nos sirve para calcular la media de los retornos para un rango establecido entre principios de año hasta la fecha actual.
Acabamos de mejorar nuestra eficiencia enormemente. Ahora lo interesante es poder ver cómo podemos tratar esos datos.
returns = ((data/data.shift(1))-1)
log_returns = np.log(1 + data.pct_change())
print(returns)
print(log_returns)
Podemos calcular la rentabilidad simple y la logarítmica de un periodo y acción y podemos imprimirlo por pantalla con print() que salvo casos excepcionales podremos obviar, ya que estas variables se guardan en memoria. Se dejan escritas para trabajar con ellas a posteriori. También podemos calcular la media anualizada de los retornos logarítmicos y las matrices de covarianzas y correlaciones, por ejemplo.
log_returns.mean()*252
log_returns.cov()*252
log_returns.corr()
print('\nMedia de los retornos logarítmicos anuales: \n' + str(log_returns.mean()*252))
print('\nMatriz de Covarianzas: \n' + str(log_returns.cov()*252))
print('\nMatriz de Correlaciones: \n' + str(log_returns.corr()))

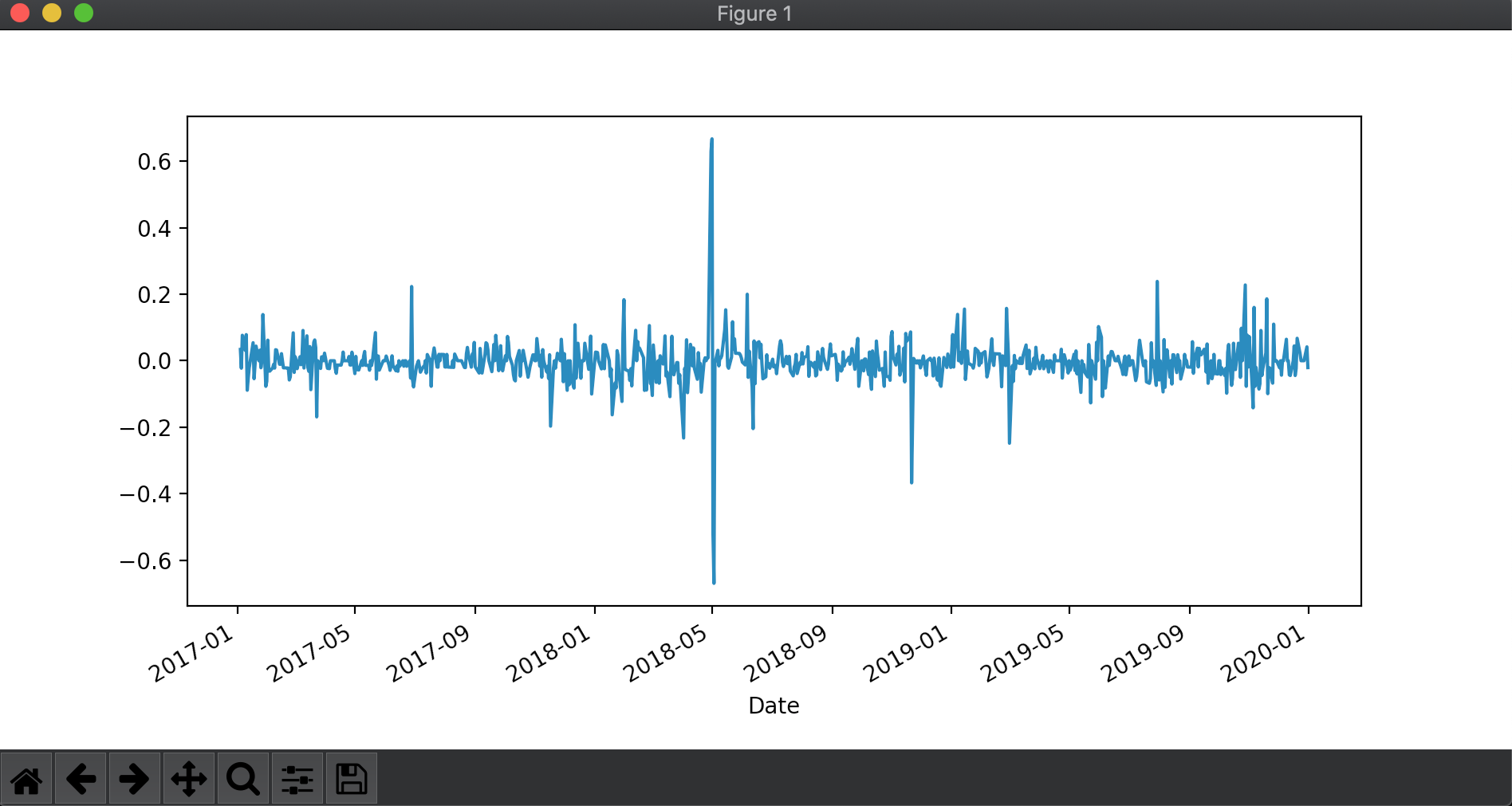
Para graficar retornos o números, podemos usar *.plot()y añadir los argumentos que nos interesen.
returns.plot(figsize=(15,6))
log_returns.plot(figsize=(15,6))
Al igual que con print, podemos mostrarlos con un plot.show() y se nos generarán con la interfaz gráfica.
Existen múltiples parámetros de configuración a la hora de mostrar los gráficos, uno de los más usados es figsize= permite establecer el tamaño del gráfico a mostrar. se pueden personalizar al gusto de cada uno según nuestras necesidades.
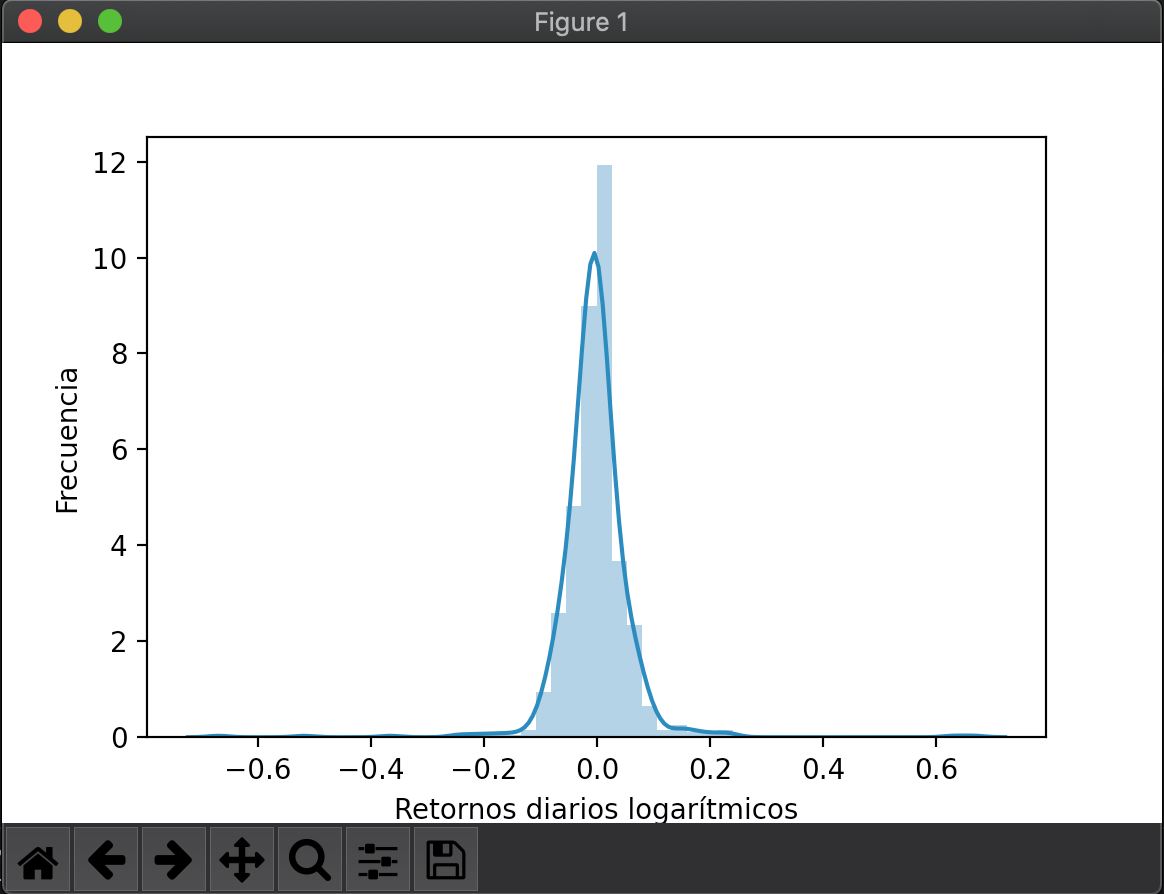
log_returns = np.log(1 + data.pct_change())
sns.distplot(log_returns.iloc[1:])
plt.xlabel("Retornos diarios logarítmicos")
plt.ylabel("Frecuencia")
plt.show()
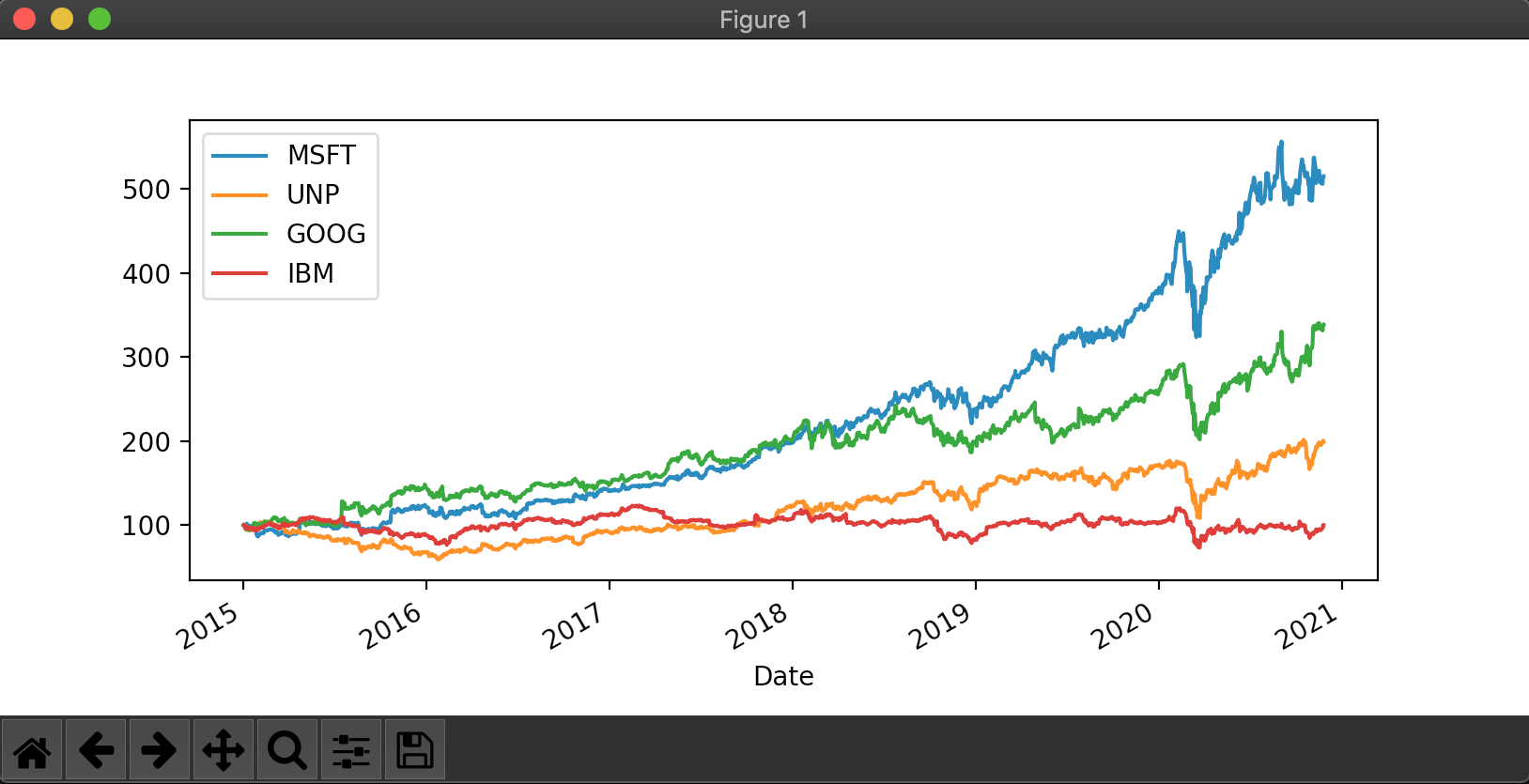
Para mostrar el de las acciones utilizamos un periodo más largo para apreciar más las diferencias a modo de ejemplo entre estas 4 empresas. Con iloc[0]*100 ajustamos el eje de las abscisas en base 100.
import numpy as np
import pandas as pd
from pandas_datareader import data as wb
import matplotlib.pyplot as plt
assets = ['MSFT','UNP','GOOG','IBM']
pf_data = pd.DataFrame()
for t in assets:
pf_data[t] = wb.DataReader(t, data_source='yahoo', start='2015-1-1')['Adj Close']
(pf_data / pf_data.iloc[0]*100).plot(figsize=(10,6))
plt.show()
![]()
1717 visitas
Categorías:
Estrategias Estadísticas Random Gestión pasiva Análisis técnico Modelos CEO Mapas mentales Liberalismo Python Growth Niusleta Ahorro Recursos humanos Inmobiliario Fiscalidad Value investing Dividendos Contabilidad Marketing Riesgo IF Cursos Opciones Bolsa